Abstract - Text mining is the procedure of synthesizing information, what is
called knowledge, by analyzing relations, patterns, and rules among textual
data. Text categorization is the procedure of assigning a category to the text
among categories predefined by users, one of the functions of text mining. The
category of the text depends on its keywords. Often, a particular text may
include the keyword of which the weight of the irrelevant category is very high.
In this case, the news article may be classified wrong by such keywords. These
keywords are called alien keywords. Alien keywords have lower substantial
weights among the selected informative keywords, and high categorical keywords
to other category. Therefore, it is proposed that the substantial weight should
be considered in the process of text categorization, not only in the process of
selecting informative keywords.
1. Introduction
The capacity of storing data becomes enormous as the technology of computer hardware develops. So the amount of data is increasing exponentially, the information required by users becomes various. It is started the research for synthesizing the information, what is called knowledge, by analyzing the relations, patterns, and rules among the stored data, with the development of artificial intelligence techniques: neural networks, genetic algorithms, knowledge representations, and fuzzy theory [3][4]. This procedure is called data mining [1][2].
Actually, users deal with textual data more frequently than numerical data. It is very difficult to apply the techniques of data mining to textual data, instead of numerical data. Therefore, it becomes necessary to develop the techniques applied to textual data differently from the numerical data in data mining. In stead of numerical data, the mining for textual data is called text mining [6][7].
Text mining is the procedure of synthesizing the information by analyzing the relations, the patterns, and the rules among the textual data. Its functions are text summarization, text categorization, and text clustering [6][7][8][9]. Text summarization is the procedure to extract its partial content reflecting its whole contents automatically. Text categorization is the procedure of assigning a category to the text among categories predefined by users. Text clustering is the procedure of segmenting texts into several clusters, depending on the substantial relevance.
The content of this paper is restricted to text categorization. To do this, documents are classified in categories manually: assigning a category to a document by scanning one's contents. Therefore it costs very much time to categorize documents manually. It is necessary to make automatic this process of text categorization. Recently, it has been researched to make text classification automatic.
Joachims proposed the application of SVM (Super Vector Machine) to text categorization [11]. Koller and Sahami researched the hierarchical classification of texts with the minimal number of keyword [12]. Sahami, Hearst, and Saund proposed the combination of supervised learning model and unsupervised learning model to text categorization [13]. Larkey and Croft applied the combined model of k-Nearest Neighbor and Baysian classifier to the categorization of medical document [14]. Lewis, Schapire, .Callan, and .Papka proposed two linear learning models, Widrow-Hoff algorithm and Exponential Gradient algorithm, for text categorization [15]. Jo proposed the scheme of text categorization based on document indexing, instead of feature extraction [16]. In the scheme presented in [16], the categorical weights of the all keyword included in the document is computed and their weights are summed as the categorical weight of the given document. The category corresponding to the largest categorical weight is assigned to the given document. But not all keywords reflect the content of the text. There are two kinds of keywords. There exist the keywords reflecting the content of the document and such keywords are called informative keywords. The others are called functional keywords or noises only functioning grammatically, not reflecting its content. Such keywords are unnecessary to categorize the document. If all keywords are used to categorize it, its efficiency becomes very poor. Jo improved this scheme by using informative keywords, instead of all keywords included in the document [17].
Often, a particular text may include keywords belonging to the category different from its category. For example, a news article about politics may include several keywords about sports. These keywords are called alien keywords in this paper. Alien keywords are the keywords belonging to the category different from the category of the given text. If such keywords are selected as informative keywords and the scheme presented in [17] is applied to text categorization, their substantial weights are relatively low among informative keywords, while their categorical weights to sports are very high. In the process of text categorization, the categorical weight to sports can be increased; even more the given news article may be classified into sports, instead of politics. This paper insists that the substantial weights of keywords be considered in the process of text categorization, not only in the process of selecting informative keywords. If the substantial weights of keywords are considered in the process of text categorization, reducing their weights for classification solves the misclassification generated by alien keywords.
In the second
section, the construction of the integrated back data and the categorical back
data will be described. The integrated back data provides the basis to assign
the substantial weight to each keyword and the categorical back data provides
the basis to assign the categorical weight to each shared keyword. In the third
section, the process of text categorization with the proposed scheme will be
explained, and the result of the comparison of the proposed scheme with the
existed scheme proposed in [17] will be presented in the fifth section. In the
sixth section, the meaning of the proposed scheme is discussed and the remaining
task to improve the scheme of text categorization will be mentioned as
conclusions.
2. Back Data
In this section, the construction of back
data providing basis for selecting informative keywords and categorizing the
documents will be described. There are two kinds of back data: integrated back
data and categorical back data. The former provides the contexts to assign
substantial weight, which means the degree of reflecting its contents.
Informative keywords are selected based on the substantial weight. The latter
does the contexts to assign categorical weights, which means the degree of
representing its category. The document is categorized based on the categorical
weights.
2.1. Integrated Back Data
Integrated back data is the back data
providing the basis for assigning the substantial weight to each word, to select
the informative keywords depending on it. The documents about all over the
fields should be added almost uniformly to construct the integrated back data.
The integrated back data can be stored as a file or a table in a particular
database. And it includes records consisting of the fields: keyword and the
accumulative number of documents including itself, among the total number of
documents added to construct the integrated back data. Therefore, the integrated
back data can be expressed as the following set of
pairs.
![]() means the set
represeting the integrated back data, and
means the set
represeting the integrated back data, and ![]() is a keyword and
is a keyword and
![]() is the
accumulative number of documents including the keyword,
is the
accumulative number of documents including the keyword,
![]() , in each pair belonging to the set
, in each pair belonging to the set
![]() . And the set,
. And the set, ![]() is assumed to be the set containing the keywords included in
the integrated back data and represented like the following this.
is assumed to be the set containing the keywords included in
the integrated back data and represented like the following this.
![]()
A document is
represented into a set of keywords by indexing it. The elements of the set,
![]() , are keywords included in the given document.
, are keywords included in the given document.
![]()
For first, the
initial back data is represented into the empty set of pairs like following
this.
![]()
The zero in the
above parenthesis means the number of documents added to construct the
integrated back data. And the integrated back data is empty initially, before
any document is added.
If ![]() is the set of
keywords included in the first document added to the empty integrated back data,
it is expressed like the following this.
is the set of
keywords included in the first document added to the empty integrated back data,
it is expressed like the following this.
![]()
And if the ![]() documents are
added, the integrated back data is assumed to be represented like the following
this.
documents are
added, the integrated back data is assumed to be represented like the following
this.
![]()
![]()
If a document is
added and the set of keywords included in it is assumed to be the set,![]() , the element of the set,
, the element of the set, ![]() , is assumed to be the keyword,
, is assumed to be the keyword,
![]() .
.
If there is the redundant keyword ![]() to the keyword
to the keyword
![]() , the pair included in the integrated back data is expressed
like the following this.
, the pair included in the integrated back data is expressed
like the following this.

As expressed
above, if there is the redundant keyword to the
keyword,![]() in the integrated back data, the accumulative number of
documents including it is incremented by one.
in the integrated back data, the accumulative number of
documents including it is incremented by one.
On contrary, if
there is no redundant keyword to ![]() , the keyword is inserted in the integrated back data and the
accumulative number of keywords corresponding to it is initialized by
one.
, the keyword is inserted in the integrated back data and the
accumulative number of keywords corresponding to it is initialized by
one.

Therefore, the
integrated back data is contructed by iterating this process.
2.2. Categorical Back Data
While the
integrated back data provides the basis of substantial weight as the measure of
selecting informative keywords, categorical back data is the back data providing
categorical back data as the measure of assigning a category to the document. To
construct the integrated back data, documents are added with the regardless of
their own categories. But the category of documents added to construct
categorical back data is homogeneous. The number of the integrated back data is
only one, while the number of the categorical back data is the number of the
predefined categories.
The set of
documents belonging to the category, ![]() , is expressed into the following set,
, is expressed into the following set, ![]() .
.
![]()
The categorical
back data corresponding to the category ![]() , contains tuples, which includes the three attributes:
keyword, the accumulative frequency, and the accumulative number of documents
including itself. Therefore, it is expressed into the set of tuples, which
includes the three attributes, like the following this.
, contains tuples, which includes the three attributes:
keyword, the accumulative frequency, and the accumulative number of documents
including itself. Therefore, it is expressed into the set of tuples, which
includes the three attributes, like the following this.
![]()
And the set of
keywords included in the categorical back data corresponding to the category
![]() is expressed like the following set,
is expressed like the following set,
![]() .
.
Like the case of
the integrated back data mentioned in the previous subsection, the categorical
back data corresponding to the category, ![]() is expressed into the empty sets to the both
sets,
is expressed into the empty sets to the both
sets, ![]() and
and ![]() , before any document is added.
, before any document is added.
![]()
The document
belonging to the category ![]() is expressed
into the following set,
is expressed
into the following set, ![]() including the tuples, which includes the two attributes:
keyword and its frequency within the document,
including the tuples, which includes the two attributes:
keyword and its frequency within the document, ![]() . Another set,
. Another set, ![]() is the set of
keywords included in the given document.
is the set of
keywords included in the given document.
![]()
![]()
In the above set,
![]() ,
, ![]() means a keyword
and
means a keyword
and ![]() does the
frequency of the keyword
does the
frequency of the keyword ![]() within the
document.
within the
document.
The categorical
back data corresponding to the category, ![]() is expressed
like the following this, when the first document is added.
is expressed
like the following this, when the first document is added.

It is assumed that
the categorical back data corresponding to the category, ![]() is expressed
like the following this, when
is expressed
like the following this, when ![]() documents are
added.
documents are
added.
![]()
![]()
If a document is
added and there is the keyword ![]() in the
categorical back data, redundant to
in the
categorical back data, redundant to ![]() inlcuded in the document, it is expressed like the following
this.
inlcuded in the document, it is expressed like the following
this.

In other words, if
there is the keyword ![]() in the categorical back data corresponding to the category
in the categorical back data corresponding to the category
![]() , redundant to the keyword
, redundant to the keyword ![]() included in the
given document, its accumulative frequency incremented with its frequency within
the document and the accumulative number of document including it is incremented
with one.
included in the
given document, its accumulative frequency incremented with its frequency within
the document and the accumulative number of document including it is incremented
with one.
If there is no
redundant keyword in the categorical back data, it is expressed like the
following this.

3. Text Categorization
In this section, the process of text categorization will be described. Like the figure 1, a particular document is indexed to a list of keyword [17]. Through the integrated back data, informative keywords are selected from the list, and a category is assigned to the document based on the categorical back data.
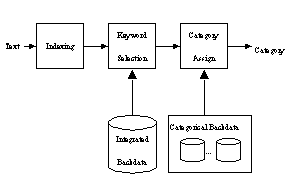
Figure 1. The Process of Text Categorization
In the figure 1, a
particular text is represented into a list of keywords by the process of
document indexing. The substantial weight, the degree of reflecting the content
of the text, is assigned to each keyword based on the integrated back data.
These keywords are sorted in the descending order of the substantial weight. The
keywords within the rank of their substantial weight are selected as informative
keywords. The rank, the measurement of selecting informative keywords, is given
as a parameter. Base on the categorical back data, the categorical weights is
assigned to each informative keyword. The categorical weight to a particular
category to a informative keyword is the accumulative number of documents or the
frequency corresponding to the keyword, if there is the keyword same to the
informative keywords from the text. If there is no such keyword in the
categorical back data to a particular category, the categorical weight of the
informative keyword is zero. The categorical weight to each category of the
informative keyword is computed with the process. To each category, the weight
of each informative keyword is computed by multiplying the categorical weight
with the substantial weight. The weights of the all selected informative
keywords are summed to each category. These weights are called the composite
weights of substantial weight and categorical weight and summed to be the
composite weight of the given text. The category that has the largest the summed
composite weight is assigned to the text.
4. Experiment & Results
In the experiment of the categorization of news articles, it shows that the proposed scheme outperforms the scheme of considering the only categorical weight. In the construction of the integrated back data, 1000 news articles from the site http://www.newspage.com/ are added with the regardless of their categories. The predefined categories are three categories: politics, sports, and business. Therefore, the number of the categorical back data becomes three. To each category, 200 documents belonging to the homogeneous category are added to construct the categorical back data. The total number of documents for the categorical back data is 600. The number of documents for tuning is 30: the number of documents per category is 10. The rank as given parameter, is 15. The number of informative keywords for the text is 15. In this experiment, the categorical weight of the keyword is based on the frequency of it or the number of documents including it. There are two kinds of errors in the categorization of news articles: wrong categorization and non-categorization. Wrong categorization means the case assigning an incorrect category to the document. Non-categorization means the case that a category can not be assigned to the document without the uniqueness of the largest composite weight of the document. In other words, if there are two or more categories that have the summed weight equal to the largest, the document can not be categorized. The measure of its performance is the precision: the ratio of the corrected categorized documents to the total documents collected for tuning. Of course, both non-categorized and wrong categorized documents are excluded. The results of the performance of text categorization are presented with the chart, like the following figure 2.
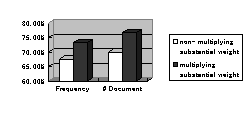
Figure 2. The results of
performance in the categorization of news articles
In the figure 2, the schemes of text categorization considering both the substantial weights and the categorical weights are over those considering only categorical weights. In the left side, "Frequency", means the categorical weight is based on the total frequency of the keyword within the category, and in the right side, "#Document", means the categorical weight is based on the number of documents including it within the category. The white bar means the case of using only the categorical weight for text categorization, while the black bar means the case of multiplying the categorical weight with the substantial weight for text categorization.
5. Conclusion
It is proposed that the substantial weights of the informative keywords be considered not only in the process of selecting informative keywords, also in the process of text categorization. The performance of text categorization is improved within the identical list of informative keywords, if their substantial weights are considered in the process of text categorization.
Alien keywords lead the text to be classified wrong, if such keywords have high categorical weights to a particular category. It is necessary that alien keywords among the selected informative keywords also be excluded, to prevent the misclassification through alien keywords.
As a remaining
task, the criteria whether the keyword is alien, should be constructed. Of
course, the alien keywords can be removed manually. To do this, the prior
knowledge about the predefined categories is necessary. And it costs very much
time to remove the alien keywords. So it is necessary to develop the scheme of
removing alien keywords automatically.
6. References
[1] M.S. Chen, J. Han, P.S. Yu, "Data Mining: An Overview from a Database Perspective", pp866-883, IEEE Transaction on Knowledge and Data Engineering Vol 8:6, 1996.
[2] K.M. Decker and S. Forcardi, "Technology Overview: A Report on Data Mining", Technical Report CSCS TR-95-02, Swiss Scientific Computing Center, 1995.
[3] N.J. Radcliffe and P.D. Surry, "Co-operation through Hierarchical Competition in Genetic Data Mining", Technical Report EPCC-TR-94-09, Edinbyrgh Parallel Computing Center, 1994.
[4] H. Lu, R. Setiono, and H. Liu, "Effective Data Mining using Neural Network", pp957-961, IEEE Transaction on Knowledge and Data Engineering Vol 8:6, 1996.
[5] V.I. Frants, J Shapiro, and V.G. Voiskunskii, Automated Information Retrieval: Theory and Methods, Academic Press, 1997.
[6] M.A. Hearst, "Text Data Mining: Issues Techniques and the Relation to Information Access", http://www.sims.berkeley.edu/~hearst/talks/dm-talk, 1997.
[7] J. Eldredge, "Text Data Mining: an Overview", http://www.cs.columbia.edu/~radev/cs6998/class/ cs6998-09-02/img001htm, 1997.
[8] A.D. Marwick, "Mining on Text Data", http://www.software.ibm.com/data/iminer/fortext/ presentations/marwick/index.htm, 1998.
[9] R. Seiffert, "Text Mining and Retrieval: A Development View", http://www.software.ibm.com/data/iminer/fortext/presentations/marwick/index.htm, 1998.
[10] D.D. Lewis, "Representation and learning in Information Retrieval", Dissertation of PhD, the Graduate School of the University of Massachusetts, 1992.
[11] T. Joachims, "Text Categorization with Support Vector Machines; learning with Many Relevant Features", LS-8 Report 23, Technical Report in University of Dortmund, 1997.
[12] D. Koller and M. Sahami, "Hierarchically Classifying Documents using very few Words", pp170-178, The proceedings of International Conference on Machine learning, 1997.
[13] M. Sahami, M. Hearst, and E. Saund, "Applying the Multiple Case Mixture Model to Text Categorization", appeared, the proceedings of International confernce on Machine Learning, 1996.
[14] L.S. Larkey and W.B. Croft, "Combining Classifiers in Text Categorization", pp289-297, The Proceedings of SIGIR 96, 1996.
[15] D.D. Lewis, R.E.Schapire, J.P.Callan, and R.Papka, "Training Algorithm for Linear Text Classifier", pp298-315, The Proceedings of SIGIR 96, 1996.
[16] T.C. Jo, "News Article Classification based on Category Points from
Keywords in Backdata", pp211-214, The Proceedings of CIMCA 99: Intelligent Image
Processing, Data Analysis & Information Retrieval edited by M. Mohammadian,
1999.
[17] T.C. Jo, "The Categorization of News Articles with Informative Keywords", submitted, The Proceedings of ITC-CSCC 99, 1999.